從零到一建設數(shù)據(jù)中臺 數(shù)據(jù)處理與存儲支持關鍵技術匯總
在數(shù)字化轉型的浪潮中,數(shù)據(jù)中臺已成為企業(yè)實現(xiàn)數(shù)據(jù)驅動、釋放數(shù)據(jù)價值的核心引擎。其核心在于將分散、異構的數(shù)據(jù)資產(chǎn)進行統(tǒng)一整合、治理與加工,形成可復用、可共享的數(shù)據(jù)服務能力,從而高效賦能前端業(yè)務。從零到一建設數(shù)據(jù)中臺,數(shù)據(jù)處理與存儲支持服務是至關重要的技術基石。本文將系統(tǒng)梳理和匯總其中的關鍵技術環(huán)節(jié)。
一、核心數(shù)據(jù)處理技術
- 數(shù)據(jù)集成與同步
- 批處理與實時流處理:建設初期需兼顧存量數(shù)據(jù)的批量遷移與增量數(shù)據(jù)的實時接入。常用工具有Apache Sqoop、DataX(批處理),以及Apache Kafka、Flink、Spark Streaming(實時流處理)。它們確保了數(shù)據(jù)從源頭系統(tǒng)到中臺的穩(wěn)定、高效流動。
- CDC(變更數(shù)據(jù)捕獲):對于數(shù)據(jù)庫源,CDC技術(如Debezium、Canal)能夠低延遲地捕獲數(shù)據(jù)的新增、更新和刪除操作,是實現(xiàn)實時數(shù)據(jù)同步、保證數(shù)據(jù)一致性的關鍵技術。
- 數(shù)據(jù)開發(fā)與計算
- 離線計算:基于Hadoop MapReduce、Apache Spark、Hive等構建大規(guī)模數(shù)據(jù)倉庫,進行復雜的ETL(抽取、轉換、加載)作業(yè)、數(shù)據(jù)清洗、指標加工和報表生成。
- 實時計算:采用Apache Flink、Spark Streaming等流計算框架,對實時數(shù)據(jù)流進行即時處理與分析,滿足實時監(jiān)控、實時推薦等業(yè)務場景。
- 交互式查詢:利用Presto、ClickHouse、Apache Kylin等引擎,支持對海量數(shù)據(jù)的亞秒級到秒級的多維分析查詢,提升數(shù)據(jù)探索與分析的效率。
- 數(shù)據(jù)治理與質量
- 元數(shù)據(jù)管理:建立統(tǒng)一的數(shù)據(jù)地圖,自動采集技術元數(shù)據(jù)(如表結構、血緣關系)和業(yè)務元數(shù)據(jù)(如指標口徑、業(yè)務術語),實現(xiàn)數(shù)據(jù)的可發(fā)現(xiàn)、可理解與可追溯。工具如Apache Atlas、DataHub。
- 數(shù)據(jù)質量:通過定義并監(jiān)控數(shù)據(jù)的完整性、準確性、一致性、及時性等規(guī)則,構建數(shù)據(jù)質量閉環(huán)。工具如Griffin、Apache Griffin或自研平臺。
- 數(shù)據(jù)標準與建模:制定企業(yè)級的數(shù)據(jù)標準與規(guī)范,并采用維度建模(如Kimball模型)或數(shù)據(jù)倉庫模型,構建清晰、穩(wěn)定的數(shù)據(jù)公共層(如貼源層、公共維度層、匯總層),這是數(shù)據(jù)資產(chǎn)可復用的核心。
二、核心數(shù)據(jù)存儲技術
- 統(tǒng)一存儲層
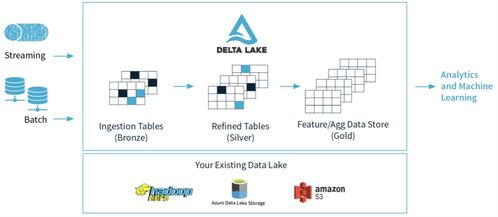
- 數(shù)據(jù)湖:以Apache HDFS、AWS S3、阿里云OSS等對象存儲為核心,構建企業(yè)級數(shù)據(jù)湖,用于原始、全量數(shù)據(jù)的低成本、高可靠存儲。它接納各種格式(結構化、半結構化、非結構化)的數(shù)據(jù),為上層計算提供統(tǒng)一的“水源”。
- 數(shù)據(jù)倉庫:在數(shù)據(jù)湖之上,基于Hive、Iceberg、Hudi或云上數(shù)倉產(chǎn)品(如MaxCompute、Snowflake),構建結構清晰、模型規(guī)范的數(shù)據(jù)倉庫,服務于系統(tǒng)性的分析與決策。
- 多樣化存儲引擎
- OLAP分析型存儲:針對不同的查詢模式,選擇合適的列式存儲引擎,如ClickHouse(極致查詢性能)、Apache Doris(兼顧實時與離線)、StarRocks等,以支持高速多維分析。
- NoSQL與寬表存儲:對于高并發(fā)點查、靈活Schema或時序數(shù)據(jù)場景,需引入HBase、Cassandra、MongoDB、時序數(shù)據(jù)庫(如InfluxDB、TDengine)等作為補充。
- 圖數(shù)據(jù)庫:對于關系挖掘、社交網(wǎng)絡、風控等場景,Neo4j、Nebula Graph等圖數(shù)據(jù)庫能高效處理復雜的關聯(lián)查詢。
三、支持服務與平臺化
- 任務調度與運維
- 采用如Apache DolphinScheduler、Airflow等調度系統(tǒng),對復雜的ETL任務流進行可視化編排、依賴管理與監(jiān)控告警,保障數(shù)據(jù)處理作業(yè)的穩(wěn)定運行。
- 數(shù)據(jù)服務與API化
- 建設統(tǒng)一的數(shù)據(jù)服務網(wǎng)關,將加工好的數(shù)據(jù)(如維度表、指標、用戶畫像標簽)封裝成標準、安全的API(Restful、GraphQL),供業(yè)務系統(tǒng)低門檻、高性能地調用,這是數(shù)據(jù)中臺價值輸出的最后一公里。
- 安全與權限
- 實施貫穿數(shù)據(jù)全生命周期的安全策略,包括存儲加密、傳輸加密、細粒度的數(shù)據(jù)訪問控制(基于RBAC或ABAC模型)、數(shù)據(jù)脫敏與審計日志,確保數(shù)據(jù)安全合規(guī)使用。
###
從零到一建設數(shù)據(jù)中臺,數(shù)據(jù)處理與存儲支持服務是貫穿始終的技術主線。企業(yè)需要根據(jù)自身的數(shù)據(jù)規(guī)模、業(yè)務場景、技術棧和團隊能力,合理選擇和組合上述關鍵技術,并注重其平臺化、服務化與自動化。關鍵在于以終為始,圍繞“數(shù)據(jù)資產(chǎn)化、服務化”的核心目標,構建一個靈活、高效、可信的數(shù)據(jù)基礎設施,從而穩(wěn)步支撐起企業(yè)數(shù)據(jù)能力的持續(xù)演進與業(yè)務創(chuàng)新的加速實現(xiàn)。
如若轉載,請注明出處:http://m.n3shop.cn/product/64.html
更新時間:2026-01-12 23:38:31